Новости AI
913
29 июля 2025 г.
Tesla A100 40GB vs A100 80GB: Как выбрать GPU для ИИ, LLM и Data Science
Когда речь заходит о работе с большими моделями искусственного интеллекта, такими как GPT-4, LLaMA, Falcon и другими LLM, выбор правильной видеокарты становится ключевым решением, влияющим на производительность и эффективность ваших задач.

Tesla A100
Содержание

NVIDIA Tesla A100 давно зарекомендовала себя как флагман среди видеокарт для серьезных вычислений, однако существует важный выбор: версия с 40 ГБ или версия с 80 ГБ видеопамяти? Сегодня детально разберем оба варианта, чтобы вы могли понять, что лучше всего подойдет именно для вашего проекта.
Почему именно Tesla A100?
NVIDIA Tesla A100 основана на архитектуре Ampere и специально разработана для высокопроизводительных вычислений (HPC), глубокого обучения (Deep Learning), машинного обучения (ML) и инференса сложных нейросетей. Она предлагает мощные вычислительные ресурсы, в том числе поддержку TF32, FP16 и INT8/INT4 операций, которые существенно ускоряют обучение и инференс нейросетей.
Однако, несмотря на общие характеристики, ключевое отличие версий A100 заключается именно в видеопамяти (её объёме и скорости). Давайте внимательно рассмотрим, как это влияет на ваши задачи.
Обзор технических характеристик Tesla A100
A100 40GB
- Видеопамять: 40GB HBM2
- Пропускная способность памяти: 1,555 ТБ/с
- CUDA-ядра: 6912
- Tensor-ядра: 432
- Поддерживаемые операции: TF32, FP16, FP64, INT8, INT4
A100 80GB
- Видеопамять: 80GB HBM2e
- Пропускная способность памяти: 2,039 ТБ/с
- CUDA-ядра: 6912
- Tensor-ядра: 432
- Поддерживаемые операции: TF32, FP16, FP64, INT8, INT4
Основные отличия и их влияние на задачи
1. Видеопамять (VRAM)
Главное и очевидное отличие — объем видеопамяти. Чем больше доступно памяти GPU, тем крупнее модель вы сможете уместить в GPU без необходимости фрагментации или offloading.
- Tesla A100 40GB подойдет для большинства распространенных задач ML, небольших и средних моделей LLM (до 30-60 млрд параметров).
- Tesla A100 80GB является идеальным выбором для очень крупных моделей, таких как GPT-4, Falcon 180B, Mixtral, а также задач, требующих обработки больших батчей или огромных контекстов данных (например, длинные последовательности в NLP или большие изображения в CV).
2. Пропускная способность памяти
Высокая пропускная способность A100 80GB (2,039 ТБ/с против 1,555 ТБ/с у 40GB) дает значительное ускорение в задачах, требующих интенсивного обмена данными с памятью GPU. Например, это становится критичным при инференсе больших нейросетей или при параллельной обработке данных.
Реальные примеры использования
Работа с крупными LLM (GPT-4, Falcon)
Большие модели типа Falcon 180B требуют много видеопамяти, и здесь версия 80GB однозначно выигрывает, позволяя загрузить модель полностью в VRAM без частичной выгрузки на оперативную память или диск, что серьезно ускоряет инференс и снижает задержки.
Глубокое обучение и fine-tuning
В задачах fine-tuning крупных нейросетей (например, LLaMA или GPT) GPU с 80 ГБ памяти позволяют обучать модели с большим размером батча, существенно ускоряя процесс и повышая качество модели.
Комплексная аналитика и обработка больших объемов данных
Если вы работаете с огромными объемами данных, где важна скорость обработки и минимальное время задержки (например, real-time аналитика), Tesla A100 80GB станет оптимальным выбором.
Тесты производительности
В реальных тестах моделей и задач:
В задачах инференса, где нужно одновременно обрабатывать множество данных или запросов, преимущество также на стороне 80GB-версии, которая стабильно поддерживает более низкую задержку.

RNN-T
При обучении больших моделей NLP (например, GPT-4 и LLaMA 70B) версия A100 80GB показала примерно на 25-40% лучше производительность по сравнению с A100 40GB, главным образом за счет возможности использовать большие батчи и избегать offloading.
Особенно заметен рост производительности в задачах обучения моделей с поддержкой FP16. DLRM (Deep Learning Recommendation Model) — отличный бенчмарк для систем с памятью большого объема. A100 80GB здесь показывает в 3 раза лучшую производительность по сравнению с 40GB.

DLRM
Как выбрать, что подходит именно вам?
A100 40GB: Идеально подойдет, если вы ограничены бюджетом и не планируете работать с очень крупными моделями. Отлично справится с задачами среднего масштаба и стандартным ML-стеком.
A100 80GB: Незаменимая инвестиция, если ваша задача включает крупные LLM, огромные датасеты, длинные контексты или если вы хотите использовать максимально возможные настройки производительности и ускорения обучения.
Вывод
Tesla A100 40GB — это мощная и надежная видеокарта для большинства задач ML и среднего уровня LLM-инференса. Однако, если вы стремитесь работать на переднем крае исследований и задач искусственного интеллекта, масштабировать модели и добиваться наивысшей эффективности, Tesla A100 80GB — это выбор, который окупится в виде сэкономленного времени и достигнутых результатов.
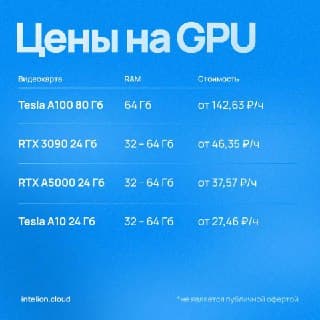
Хотите сами проверить A100 на практике?
Арендуйте GPU серверы в Интелион Облако: доступ к Tesla A100 80GB, удобное подключение и почасовая оплата. Тестируйте, выбирайте и оптимизируйте ваши задачи.
Новости AI
#A100
#A100 40GB vs 80GB
#Сравнение видеокарт