Новости AI
812
15 июля 2025 г.
Зачем вам нужна Tesla A100 80 ГБ — и почему в «Интелион Облако» она раскрывается на максимум
Теперь Tesla A100 80 GB доступна в аренду на серверах «Интелион Облако», и это не просто очередное «мы добавили карточку». Это целый новый класс задач, который вы можете решать в пару кликов.

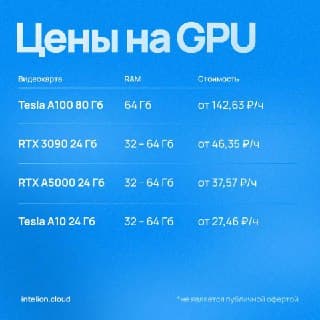
Tesla A100
Содержание

Когда ИИ становится основой продукта, а не просто экспериментом — наступает момент, когда RTX серия уже не тянет. И даже A10 с её 24 ГБ начинает задыхаться на батче 64k. Здесь вступает в игру NVIDIA Tesla A100 80 ГБ — ускоритель, созданный не для гейминга, а для настоящих вычислений, больших моделей и реального времени.
Что такое Tesla A100 и почему она так важна?
A100 — это не просто GPU, а вычислительный модуль для централизованных, интенсивных задач. Она построена на архитектуре NVIDIA Ampere, поддерживает тензорные ядра третьего поколения, TF32, FP16, FP8, BF16 и INT4, а также обладает гигантской памятью — 80 ГБ HBM2e.

Характеристики A100
Эта видеокарта не имеет HDMI, не выводит картинку и не рендерит в Unreal Engine. Она создана для обучения и инференса LLM, научных расчётов, работы с данными в реальном времени и высоконагруженных задач HPC (High Performance Computing).
Когда RTX уже не справляется: задачи, в которых A100 незаменима
Обработка больших языковых моделей (LLM)
- Обучение и инференс Llama 3 70B, Mixtral, Gemma, GPT-J, Yi-34B и аналогов
- Генерация с контекстом в 100k+ токенов без обрезки
- Мгновенное сворачивание моделей в режимы INT4 / FP8 без потери производительности
- Тестирование и запуск multi-agent-сценариев, включая AutoGPT, AgentScope, LangGraph
Научные и численные вычисления (HPC)
- Моделирование физических процессов и молекулярной динамики
- Расчёт больших матриц и симуляций
- Интенсивное использование тензорных операций с двойной точностью
Генерация и обучение визуальных моделей
- Обучение кастомных моделей Stable Diffusion XL, SD Turbo, PaliGemma, VideoCrafter2
- Поддержка кустарного fine-tune с низкой точностью на гигантских датасетах
- Поддержка долгосрочной inference-подачи в real-time-продуктах
Аналитика и Data Science
- Быстрая визуализация и агрегация массивов до 2 ТБ
- Работа с векторными базами и embedding'ами в LLM-интеграции (RAG)
Что под капотом в Интелион Облако
Мы не просто добавили A100 в прайс-лист. Мы собрали под неё плотные серверы с расчётом на нагрузку:
- до 4× Tesla A100 80 ГБ в одном узле
- ЦП — Intel Xeon Gold 6336Y (2.4–3.6 ГГц, AVX-512 + Deep Learning Boost)
- до 768 ГБ оперативной памяти DDR4 ECC Reg
- локальное хранилище: до 2 ТБ на SSD уровня дата-центров Intel®
И всё это — в иммерсионном охлаждении, чтобы даже 100% загрузка на несколько дней не сбивала температуру и частоту.
Почему это важно именно сейчас?
Модели растут. Даже inference современных LLM требует 40+ ГБ VRAM. A10 с её 24 ГБ не тянет без offload'а.
Время — деньги. A100 экономит часы на каждом fine-tune или генерации.
Гибкость масштабирования. Хотите собрать кластер — берёте сразу 2 или 4 A100. Хотите просто быстро погонять модель — арендуете на месяц, без капекса.
Выход за границы Colab и HuggingFace: теперь ваш проект не тормозит из-за «переиспользованных слотов».
Вывод
Если ваша нейросеть начинает «не влезать», а обучение — растягиваться на недели, значит, пришло время переходить на следующий уровень вычислений. Tesla A100 80 ГБ — не роскошь, а необходимость для задач, которые действительно важны.
Попробуйте A100 80 ГБ в Интелион Облако прямо сейчас
Мы сдаём их на месяцы, без перегрузки и с полной техподдержкой. Настроим сервер под вашу модель, поможем развернуть окружение и запустить инференс или обучение на полную катушку.
Новости AI
#Flux
#HuggingFace
#Inference
#Tesla A100
#Видеокарты