Новости AI
1.8K
6 августа 2025 г.
Как посчитать VRAM для LLM: подробный гайд по расчету видеопамяти для моделей машинного обучения
Модели машинного обучения стали неотъемлемой частью современной разработки. Давайте разберемся как выбрать видеокарту для своей LLM.

Калькулятор VRAM
Содержание

Сегодня невозможно представить крупный технологический проект без использования нейросетей, будь то генерация текстов, чат-боты, интеллектуальные помощники или системы рекомендаций. Но вместе с ростом сложности моделей возрастают и требования к вычислительным ресурсам. Важнейший аспект здесь — точный расчет VRAM (видеопамяти GPU) для запуска LLM и других моделей машинного обучения.
В этой статье подробно разберём, как правильно рассчитать необходимый объём VRAM для популярных моделей, как оптимизировать её использование, и когда выгоднее арендовать сервер с GPU вместо покупки собственного железа.
Почему важно правильно рассчитывать VRAM?
Каждый, кто сталкивался с запуском моделей вроде GPT-4, LLaMA, Mistral или Claude, прекрасно знает проблему переполнения памяти GPU. Вы запускаете модель, и вместо ожидаемого результата получаете ошибку:
RuntimeError: CUDA out of memory.
Правильный расчет VRAM важен по нескольким причинам:
- Эффективность затрат: если вы покупаете или арендуете серверы, правильный расчёт позволяет выбрать оптимальное железо, избегая переплат.
- Производительность модели: нехватка памяти приводит к нестабильности работы и низкой скорости генерации.
- Экономия времени на эксперименты: избегаете ненужных проблем при запуске моделей и можете сосредоточиться на задачах машинного обучения.
Давайте перейдём к практике.
VRAM LLM calculator
Расчёт VRAM основывается на следующей общей формуле:
VRAM = Количество параметров модели × Размер типа данных × Дополнительные множители
Что означают эти переменные?
- Количество параметров — главный показатель размера модели (например, 7B, 13B, 70B).
- Размер типа данных — сколько памяти занимает один параметр (float32 — 4 байта, float16 — 2 байта, INT8 — 1 байт, INT4 — 0.5 байта).
- Дополнительные множители — учитывают токены контекста, промежуточные вычисления, активации и другие технические нюансы.
Пример расчета для популярной модели LLaMA 7B (7 миллиардов параметров):
- Параметры модели: 7 миллиардов
- Тип данных: FP16 (float16 — 2 байта на параметр)
- Дополнительный множитель (активации и буфер токенов): около 1.2–1.5 (с запасом)
Считаем:
7000000000×2байта×1.5=21000000000байт (около 21 GB)
Таким образом, для комфортного запуска модели LLaMA 7B с FP16 нужно минимум 24 GB VRAM.
Практические расчёты для разных моделей и типов данных
Рассмотрим три типичных размера моделей и влияние квантизации (уменьшение размера параметров за счет снижения точности):

LLM
Квантизация существенно снижает потребность в видеопамяти без потери значительного качества для многих задач машинного обучения.
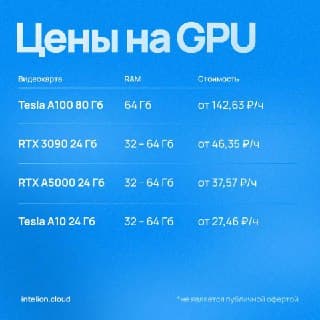
Вот несколько рекомендаций по моделям видеокарт и параметрам LLM:

Видеокарты для LLM
Методы оптимизации VRAM для запуска LLM
Кроме квантизации есть и другие подходы, позволяющие сократить использование памяти GPU:
- Градиентный checkpointing (Gradient checkpoint) — позволяет экономить VRAM при обучении моделей за счет повторного вычисления некоторых промежуточных состояний вместо их хранения.
- LoRA (Low Rank Adaptation) — техника дообучения, которая снижает расход памяти, позволяя обучать модели на бюджетных GPU.
- Параллелизм моделей (Model parallelism) — распределение модели на несколько GPU, если модель не влезает в память одного устройства.
Эти методы активно используются в реальных проектах Data Science, где задачи машинного обучения связаны с ограниченными ресурсами.
Практическое применение: аренда GPU против покупки
Теперь о бизнесе. Для многих стартапов, исследователей и разработчиков с pet-проектами в области Data Science покупка собственного GPU-сервера нерентабельна.
- Покупка своего GPU:
- Высокий стартовый капитал
- Расходы на электричество и охлаждение
- Необходимость постоянного обслуживания
- Аренда GPU для машинного обучения:
- Низкие начальные вложения
- Возможность почасовой оплаты — платите только за использование
- Легкое масштабирование — можно выбрать сервер под конкретные задачи и эксперименты
Если вы хотите запустить нейросеть на несколько часов или дней, аренда GPU облачных мощностей всегда выгоднее.
Полезные инструменты и калькуляторы для расчета VRAM
Python-скрипты для автоматического расчета VRAM — доступны на GitHub и позволяют быстро получить расчёт.
Онлайн-калькуляторы VRAM — помогают быстро проверить, сколько видеопамяти нужно под конкретную модель.
Пример Python-скрипта (упрощённый):
# Расчет VRAM для LLaMA 13B FP16
parameters = 13e9
bytes_per_param = 2 # FP16
buffer_multiplier = 1.5
vram_required_gb = parameters * bytes_per_param * buffer_multiplier / (1024 ** 3)
print(f"VRAM required: {vram_required_gb:.2f} GB")
Заключение и рекомендации
Резюмируем:
- Точный расчет VRAM обязателен для стабильного запуска LLM.
- Используйте квантизацию и методы оптимизации, чтобы снизить потребности в GPU.
- Почасовая аренда GPU серверов идеальна для стартапов, исследователей и pet-проектов, которые хотят экономить время и деньги.
Если вы начинаете свой путь в машинном обучении и хотите экспериментировать без больших затрат, аренда сервера с GPU — ваш выбор.
Интелион Облако предлагает GPU-серверы с оплатой по секундам, гибкими конфигурациями (A100, A10, A5000, RTX 3090) и скидками до 30% в зависимости от срока аренды.
Попробуйте свои модели на практике и убедитесь, что машинное обучение может быть доступным и простым в использовании.
Новости AI
#data science
#LLM
#machine learning
#Видеокарта для LLM