Из ТГ канала

Быстрая русскоязычная LLM с качественными ответами
Адаптированная RuadaptQwen3-4B-Instruct — быстрая, компактная и с сохранением всех сильных сторон исходной модели. Более того, в некоторых тестах Ruadapt даже превосходит оригинал по качеству ответов.
Почему это важно?
☹️Скорость выше, ресурсы ниже: Новая модель заметно экономнее использует память и быстрее отвечает — идеальна для запуска на локальных GPU и даже CPU.
☹️Точность на высоте: По отдельным метрикам (в частности, на типичных задачах инструкций и разговоров) RuadaptQwen3-4B-Instruct стабильно показывает лучшие результаты, чем исходная модель от Qwen3.
☹️Удобство деплоя: Доступна в форматах PyTorch и GGUF, готова к запуску на любых мощностях — от облака до ноутбука.
☹️ Скачивайте и тестируйте:
RuadaptQwen3-4B-Instruct (PyTorch)
RuadaptQwen3-4B-Instruct (GGUF)
🎁 Уже 5 июля подведем итоги розыгрыша серверов в Интелион Облако — можно сразу запустить RuadaptQwen3-4B локально и убедиться в её преимуществах лично!
🙂 Artificial Intelion
Новости AI
#ии
#нейросети
#llm
Рекомендуем прочесть:
- Как посчитать VRAM для LLM: подробный гайд по расчету видеопамяти для моделей машинного обучения
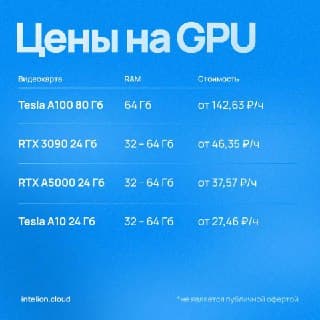
- Tesla A100 40GB vs A100 80GB: Как выбрать GPU для ИИ, LLM и Data Science
- Что такое GPU сервер и как его арендовать?
- Tesla A10 vs RTX 3090 — оптимальный выбор GPU для ваших нейросетей
- Зачем вам нужна Tesla A100 80 ГБ — и почему в «Интелион Облако» она раскрывается на максимум